January 23, 2025
Understanding Linear Regression

In this blog, we will deep dive into the most basic Machine Learning Algorithm, and that is, Linear Regression. This is the first algorithm you learn as a student of ML. We will first understand the logic and concept behind this algorithm and then will learn to code it as well. So, Let's get started.
First, let's develop the intuition for the model. So, Consider the problem given below.
You want to predict the price of a house based on its size (in square feet). You collect the following data from a small neighborhood:
Size (sq ft) Price (in $1,000s)
--------------------------------
800 150
1000 200
1200 250
1500 300
1800 400
2000 450
2200 500
2500 600
2800 700
3000 750
Now, let's say you want to predict the price for a house of size 2150 sq. ft.
First, I would like to visualize this data. We will use Python for that and alongside we will learn Linear regression.
So, I have entered this data into a file and saved it as a csv file on my laptop. So, I am going to import that file and then use matplotlib to plot a scatter plot .
Why Scatter Plot? Basically, I wish to see all the ten data points when plotted on x-y graph, so that I can think about predicting values by finding the optimal relation.
Here is the code for same.
Here is the scatter plot.
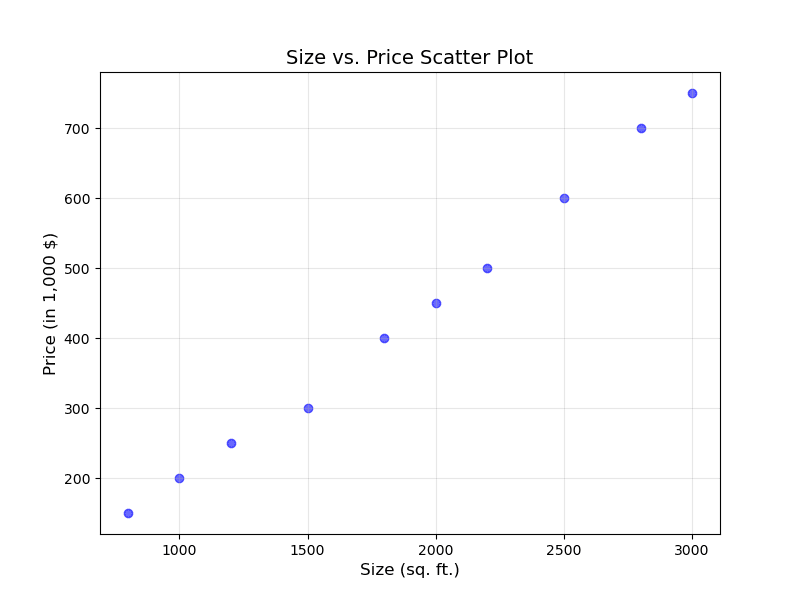
So, we got the scatter plot. Now, to predict the price of plot given the size of plot, we need a relationship between the two variables. So, what's the simplest way. Simplest thing is that we find a linear relation. But as we can see that there is no clear straight line joining all the ten points. (If it would have been, it won't be a machine learning task). What we do? We find the optimal straight line fitting all these points. (Not necessarily passing through all of them).
And this is the ides of Linear Regression. The idea behind Linear Regression is to model the relationship between features and target variables as a straight line, i.e., a linear equation.
Let's stop here and understand what Target and Feature variables are. Target variable is the quantity you aim to predict and Feature variables are those which are used to predict the target. In this Example, Size is a feature variable, and Price is a target variable.
Now, as we know what is the idea of Linear Regression, let's study how does it work and find the optimal linear relation? So, recall the slope-intercept form of straight-line equation. It is "y=mx+c". So, we first assume our straight line to be "y=wx+c", where w and b are constants and y is our target variable (price) and x is our feature(size). To find the straight line, we need to find the values of w and b.
Step1: Initialize random values for w and c. First, we assign random values to these two parameters 'w' and 'c'.
Step2: Now, for sure, there would be an error. So, we calculate Mean Squared Error (MSE), which is our loss function here. The formula to calculate the same is as follows

where n is the number of observations yi is the actual value of ith observation and yi^(yi hat) is the predicted value for ith observation
Step3: Gradient Descent -: Now, our loss function (or MSE) will be a function of 'w' and 'c'. We find it's partial derivative with respect to both the variables and use it to update the values of 'w' and 'b'. This technique is called Gradient Descent. The objective of using Gradient Descent is to minimize the loss function.
the equations used to update the values of 'w' and 'b' are as follows:

Note L signifies nothing but the MSE.
One thing to note here is n(eta). It is called learning rate. It is set by us and we can choose it's value according to us. The usual value ranges from 0.001 to 0.1. Optimally, we can take the value as 0.01. Learning rate signifies how fast does the model learn, or, we say updates the value of w and b. If the value of learning rate is small, there will be smaller changes in the value of 'w' and 'b' on each iteration. On the other hand, if learning rate is large, model will learn quickly, that is, there will be larger changes in values of 'w' and 'b' on each iteration.
Remember, Learning Rate is a hyperparameter. We can solve the problem of overfitting and underfitting the data set by finding the optimal value of hyperparameter. This is called Hyperparameter Tuning and is a whole new topic of discussion. We will cover it in another blog.
So, in short, we first assign random values to 'w' and 'b'. Then, we find the loss function and use gradient descent to update values of 'w' and 'b'. We keep on updating the values of 'w' and 'b' until we minimize the loss function.
Now, let's come to the last part-" Implementing Linear Regression". All the math we just went through was just to build understanding, we need not to write code for any of the steps. We can simply use Python's Scikit Learn library. We use the LinearRegression function from this library. Code to implement it for our problem is as follows:
Now, we have a trained model to make predictions.Now, let's ask it to make the prediction.
The predicted value I get on running this code is 500.07 (in 1,000$). You will notice that price of 2200 sq. ft. house is 500 (in 1,000$) which is lesser than that of 2150 sq.ft. Let's visualize our straight line .
Output:
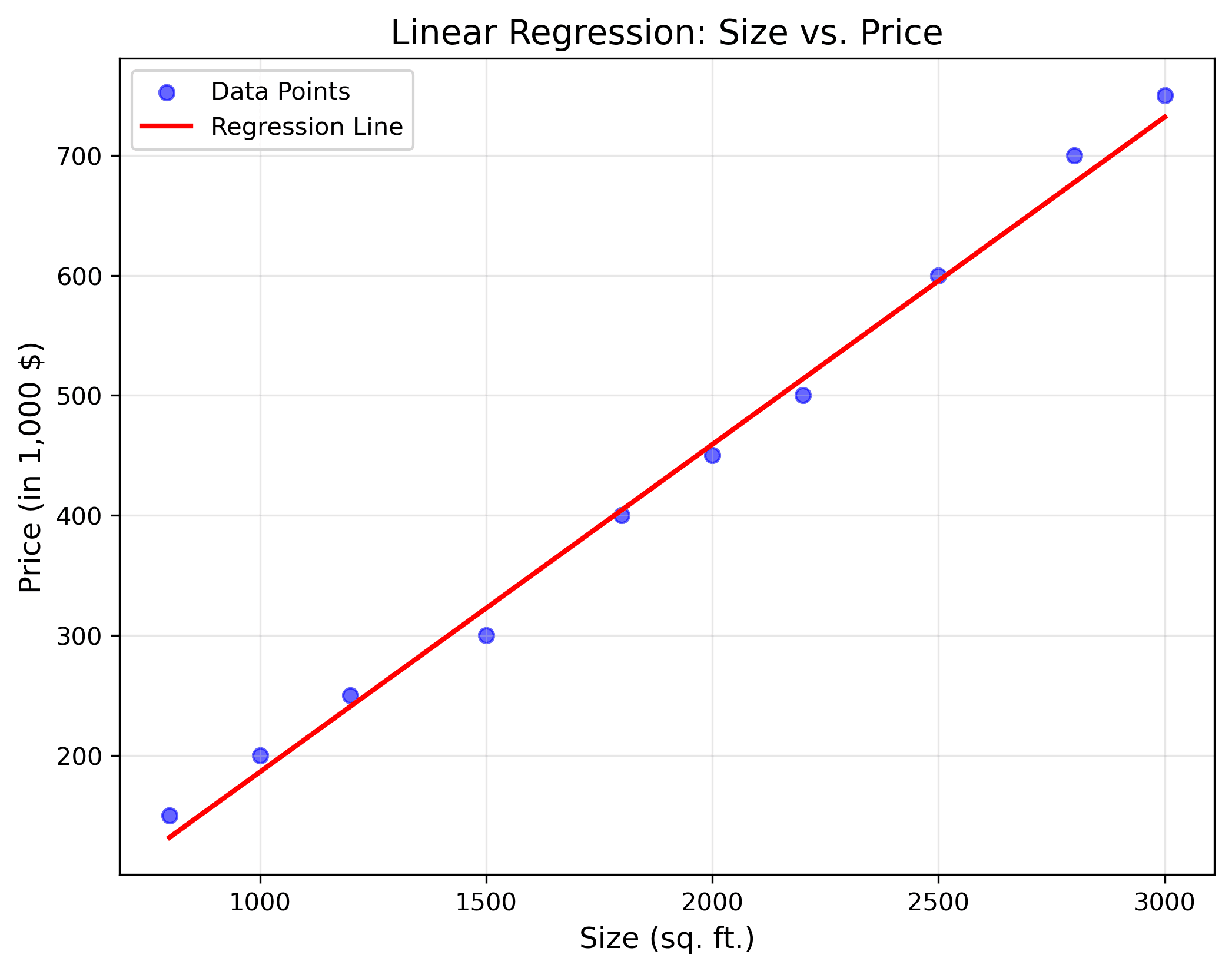
As you can notice, our straight line is not passing through every point, but it is just fitting all the points . This straight line has tried to minimize its distance from all the data points, or in other words, the loss function.
You can yourself see the results by copy pasting this code. You can download different datasets from Kaggle and try implementing Linear Regression models.
This was Linear Regression with just one feature variable. But it is not the case always. We can have multiple feature variables. I will cover Linear Regression with multiple feature variable in another blog. So, stay tuned with me.



